
serviceworker运用与实践
前言
本文首先会简单介绍下前端的常见缓存方式,再引入serviceworker的概念,针对其原理和如何运用进行介绍。然后基于google推出的第三方库workbox,在产品中进行运用实践,并对其原理进行简要剖析。
前端缓存简介
先简单介绍一下现有的前端缓存技术方案,主要分为http缓存和浏览器缓存。
http缓存
http缓存都是第二次请求时开始的,这也是个老生常谈的话题了。无非也是那几个http头的问题:
Expires
HTTP1.0的内容,服务器使用Expires头来告诉Web客户端它可以使用当前副本,直到指定的时间为止。
Cache-Control
HTTP1.1引入了Cathe-Control,它使用max-age指定资源被缓存多久,主要是解决了Expires一个重大的缺陷,就是它设置的是一个固定的时间点,客户端时间和服务端时间可能有误差。
所以一般会把两个头都带上,这种缓存称为强缓存,表现形式为:

Last-Modified / If-Modified-Since
Last-Modified是服务器告诉浏览器该资源的最后修改时间,If-Modified-Since是请求头带上的,上次服务器给自己的该资源的最后修改时间。然后服务器拿去对比。
若资源的最后修改时间大于If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码200;
若资源的最后修改时间小于或等于If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用当前版本。
Etag / If-None-Match
前面提到由文件的修改时间来判断文件是否改动,还是会带来一定的误差,比如注释等无关紧要的修改等。所以推出了新的方式。
Etag是由服务端特定算法生成的该文件的唯一标识,而请求头把返回的Etag值通过If-None-Match再带给服务端,服务端通过比对从而决定是否响应新内容。这也是304缓存。
浏览器缓存
storage
简单的缓存方式有cookie,localStorage和sessionStorage。这里就不详细介绍他们的区别了,这里说下通过localStorage来缓存静态资源的优化方案。
localStorage通常有5MB的存储空间,我们以微信文章页&version=12020810&nettype=WIFI&lang=zh_CN&fontScale=100&pass_ticket=b33mKzDsMeDiiLYT97yWzaAceoFf%2Fly7szwZmE%2F62%2BtvutX3nrerhLuye%2BwpBGCb)为例。
查看请求发现,基本没有js和css的请求,因为它把全部的不需要改动的资源都放到了localStorage中:
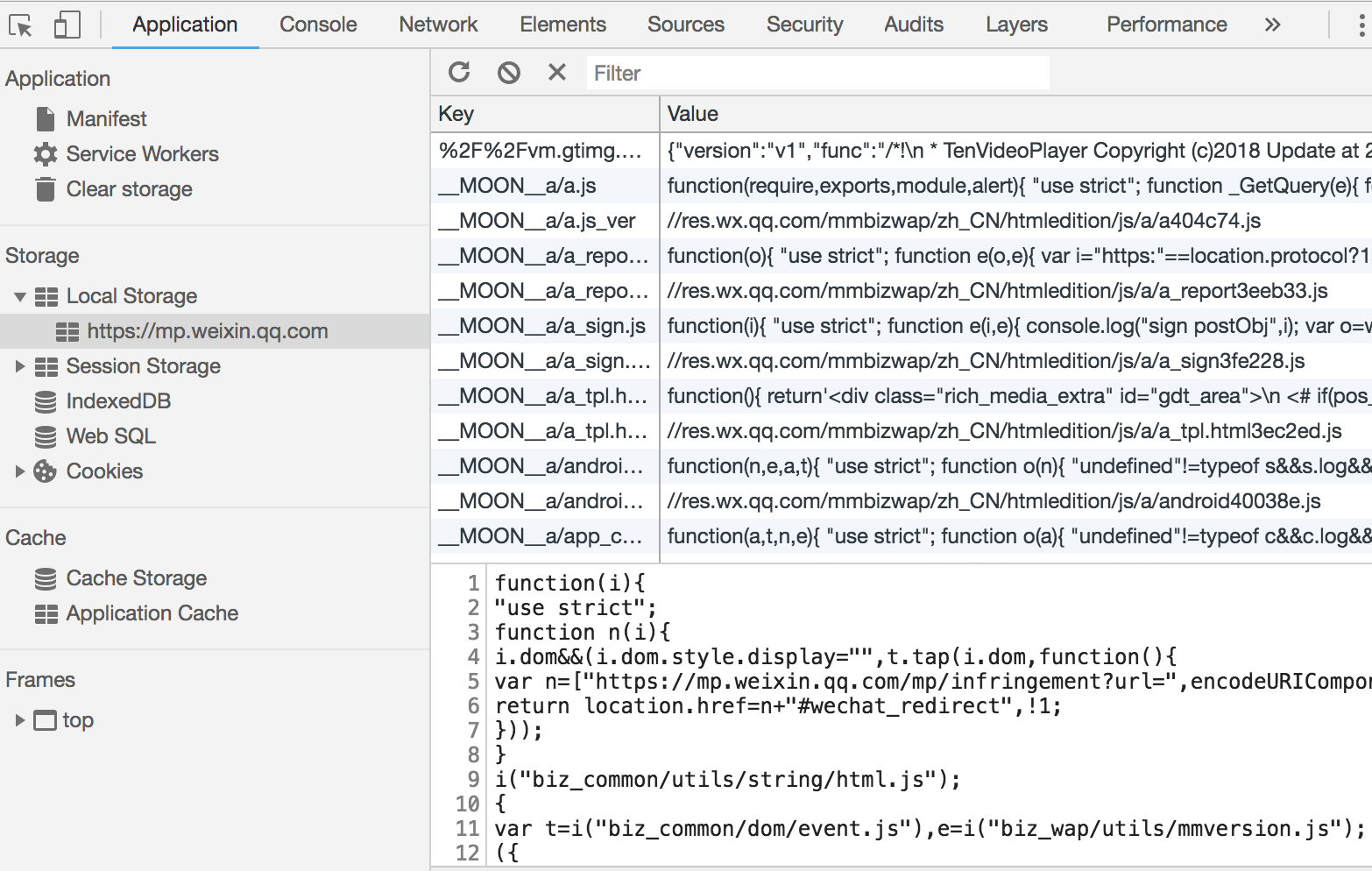
所以微信的文章页加载非常的快。
前端数据库
前端数据库有WebSql和IndexDB,其中WebSql被规范废弃,他们都有大约50MB的最大容量,可以理解为localStorage的加强版。
应用缓存
应用缓存主要是通过manifest文件来注册被缓存的静态资源,已经被废弃,因为他的设计有些不合理的地方,他在缓存静态文件的同时,也会默认缓存html文件。这导致页面的更新只能通过manifest文件中的版本号来决定。所以,应用缓存只适合那种常年不变化的静态网站。如此的不方便,也是被废弃的重要原因。
PWA也运用了该文件,不同于manifest简单的将文件通过是否缓存进行分类,PWA用manifest构建了自己的APP骨架,并运用Servie Worker来控制缓存,这也是今天的主角。
Service Worker
Service Worker本质上也是浏览器缓存资源用的,只不过他不仅仅是cache,也是通过worker的方式来进一步优化。
他基于h5的web worker,所以绝对不会阻碍当前js线程的执行,sw最重要的工作原理就是
1、后台线程:独立于当前网页线程;
2、网络代理:在网页发起请求时代理,来缓存文件;
兼容性

可以看到,基本上新版浏览器还是兼容滴。之前是只有chrome和firefox支持,现在微软和苹果也相继支持了。
成熟程度
判断一个技术是否值得尝试,肯定要考虑下它的成熟程度,否则过一段时间又和应用缓存一样被规范抛弃就尴尬了。
所以这里我列举了几个使用Service Worker的页面:
所以说还是可以尝试下的。
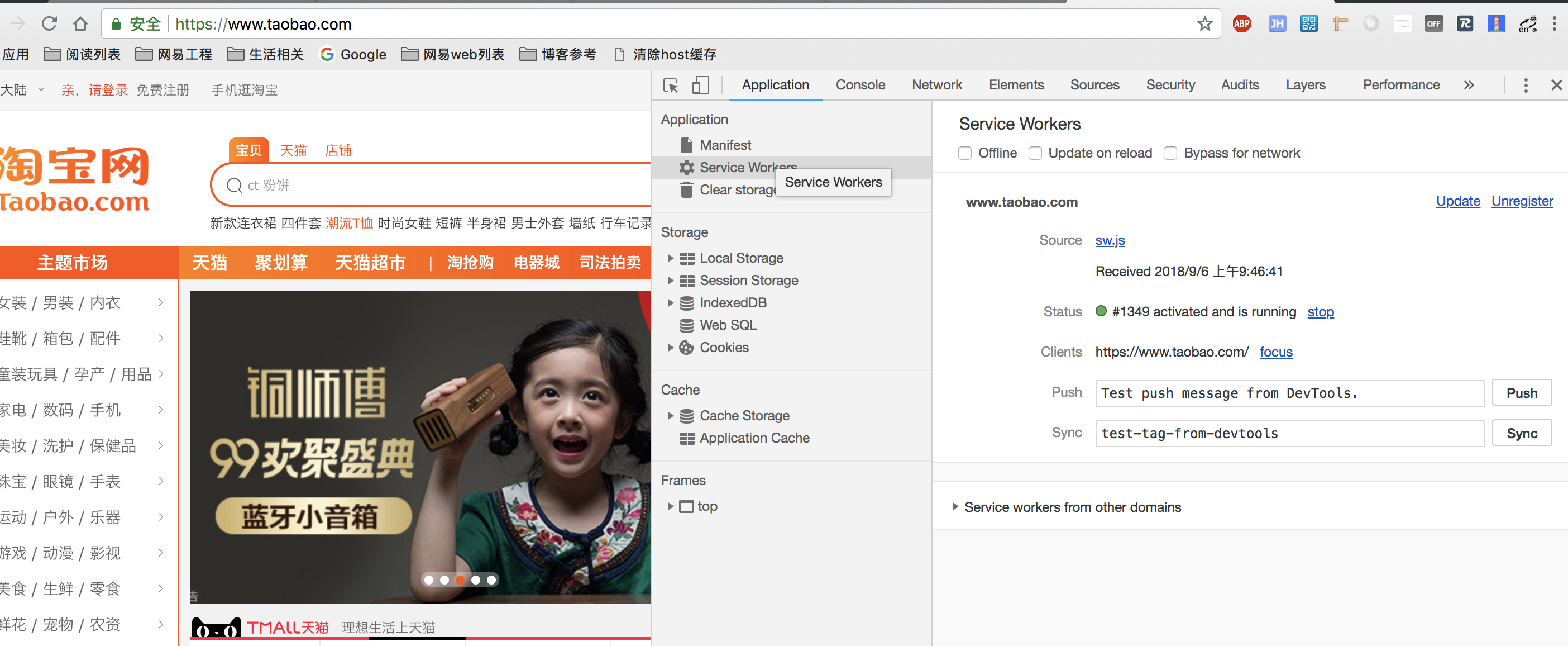
调试方法
一个网站是否启用Service Worker,可以通过开发者工具中的Application来查看:
被Service Worker缓存的文件,可以在Network中看到Size项为 from ServiceWorker:

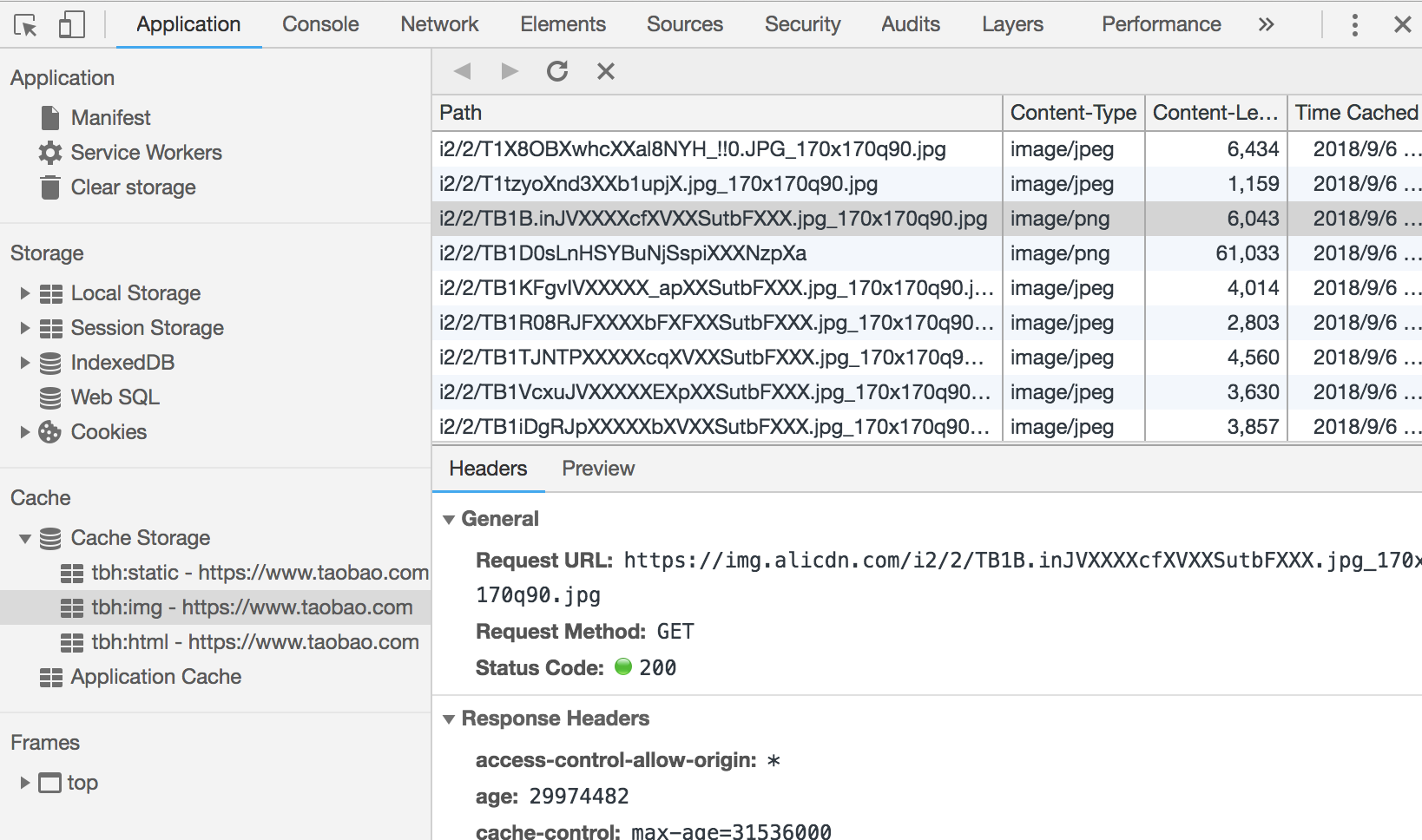
也可以在Application的Cache Storage中查看缓存的具体内容:
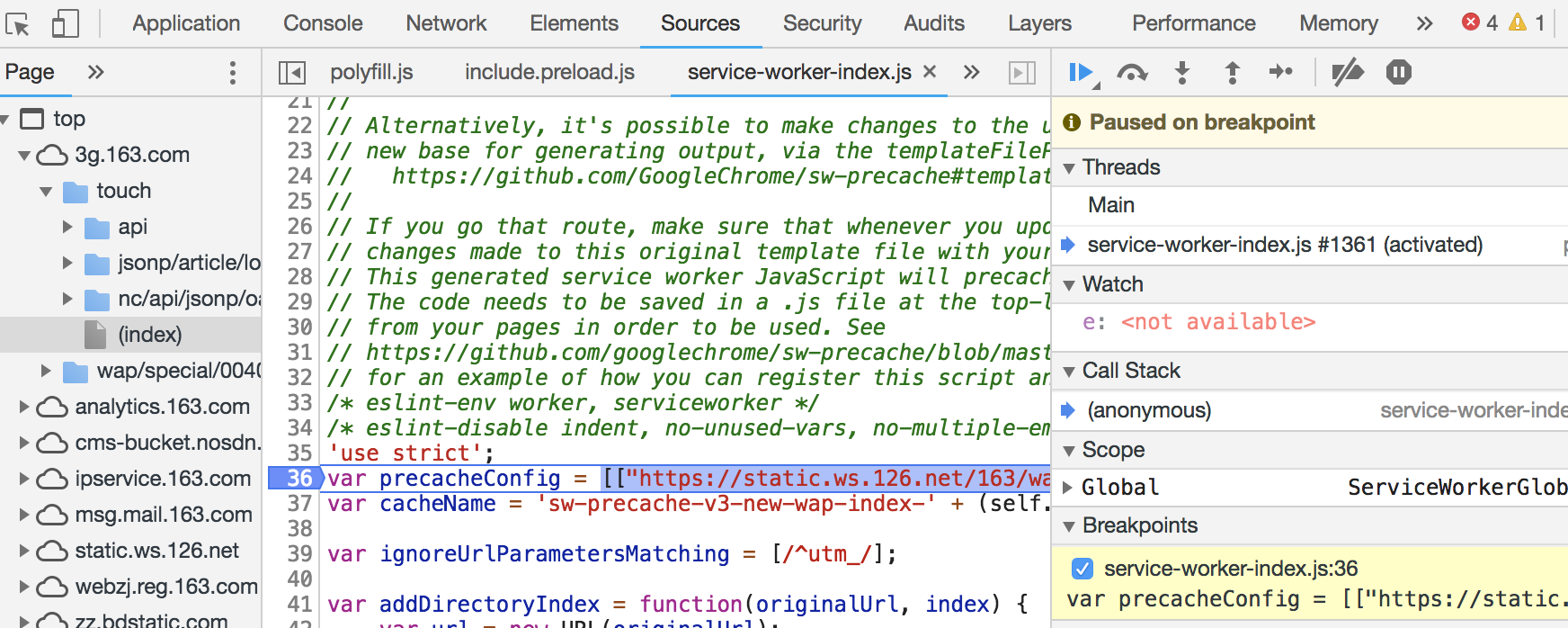
如果是具体的断点调试,需要使用对应的线程,不再是main线程了,这也是webworker的通用调试方法:
使用条件
sw 是基于 HTTPS 的,因为service worker中涉及到请求拦截,所以必须使用HTTPS协议来保障安全。如果是本地调试的话,localhost是可以的。
而我们刚好全站强制https化,所以正好可以使用。
生命周期
大概可以用如下图片来解释:
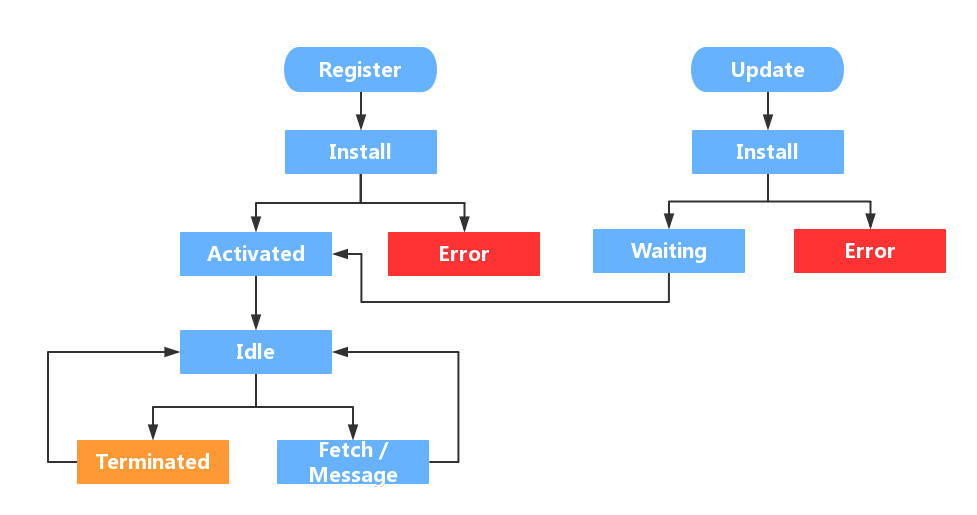
注册
要使用Service worker,首先需要注册一个sw,通知浏览器为该页面分配一块内存,然后sw就会进入安装阶段。
一个简单的注册方式:
(function() {if('serviceWorker' in navigator) {navigator.serviceWorker.register('./sw.js');}})()
当然也可以考虑全面点,参考网易新闻的注册方式:
"serviceWorker" in navigator && window.addEventListener("load",function() {var e = location.pathname.match(/\/news\/[a-z]{1,}\//)[0] + "article-sw.js?v=08494f887a520e6455fa";navigator.serviceWorker.register(e).then(function(n) {n.onupdatefound = function() {var e = n.installing;e.onstatechange = function() {switch (e.state) {case "installed":navigator.serviceWorker.controller ? console.log("New or updated content is available.") : console.log("Content is now available offline!");break;case "redundant":console.error("The installing service worker became redundant.")}}}}).catch(function(e) {console.error("Error during service worker registration:", e)})})
前面提到过,由于sw会监听和代理所有的请求,所以sw的作用域就显得额外的重要了,比如说我们只想监听我们专题页的所有请求,就在注册时指定路径:
navigator.serviceWorker.register('/topics/sw.js');
这样就只会对topics/下面的路径进行优化。
installing
我们注册后,浏览器就会开始安装sw,可以通过事件监听:
//service worker安装成功后开始缓存所需的资源var CACHE_PREFIX = 'cms-sw-cache';var CACHE_VERSION = '0.0.20';var CACHE_NAME = CACHE_PREFIX+'-'+CACHE_VERSION;var allAssets = ['./main.css'];self.addEventListener('install', function(event) {//调试时跳过等待过程self.skipWaiting();// Perform install steps//首先 event.waitUntil 你可以理解为 new Promise,//它接受的实际参数只能是一个 promise,因为,caches 和 cache.addAll 返回的都是 Promise,//这里就是一个串行的异步加载,当所有加载都成功时,那么 SW 就可以下一步。//另外,event.waitUntil 还有另外一个重要好处,它可以用来延长一个事件作用的时间,//这里特别针对于我们 SW 来说,比如我们使用 caches.open 是用来打开指定的缓存,但开启的时候,//并不是一下就能调用成功,也有可能有一定延迟,由于系统会随时睡眠 SW,所以,为了防止执行中断,//就需要使用 event.waitUntil 进行捕获。另外,event.waitUntil 会监听所有的异步 promise//如果其中一个 promise 是 reject 状态,那么该次 event 是失败的。这就导致,我们的 SW 开启失败。event.waitUntil(caches.open(CACHE_NAME).then(function(cache) {console.log('[SW]: Opened cache');return cache.addAll(allAssets);}));});
安装时,sw就开始缓存文件了,会检查所有文件的缓存状态,如果都已经缓存了,则安装成功,进入下一阶段。
activated
如果是第一次加载sw,在安装后,会直接进入activated阶段,而如果sw进行更新,情况就会显得复杂一些。流程如下:
首先老的sw为A,新的sw版本为B。
B进入install阶段,而A还处于工作状态,所以B进入waiting阶段。只有等到A被terminated后,B才能正常替换A的工作。
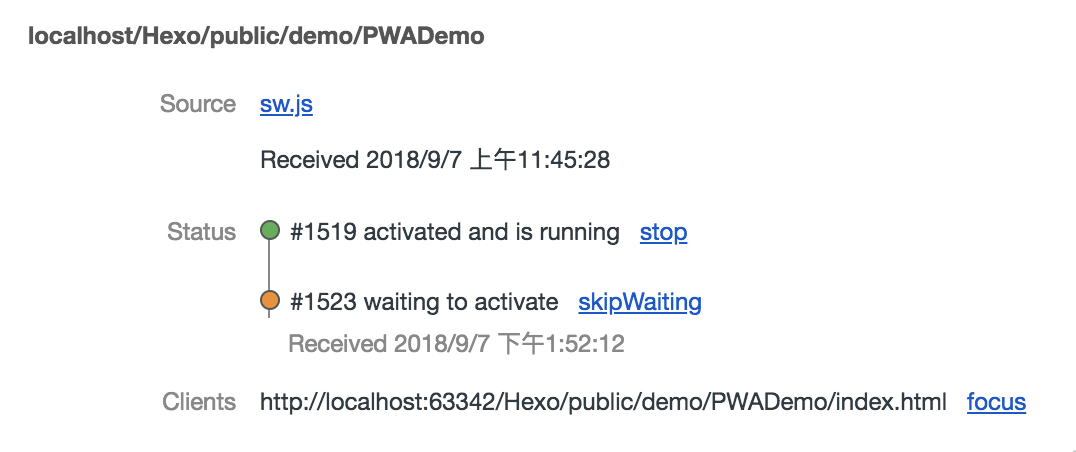
这个terminated的时机有如下几种方式:
1、关闭浏览器一段时间;
2、手动清除serviceworker;
3、在sw安装时直接跳过waiting阶段
//service worker安装成功后开始缓存所需的资源self.addEventListener('install', function(event) {//跳过等待过程self.skipWaiting();});
然后就进入了activated阶段,激活sw工作。
activated阶段可以做很多有意义的事情,比如更新存储在cache中的key和value:
var CACHE_PREFIX = 'cms-sw-cache';var CACHE_VERSION = '0.0.20';/*** 找出对应的其他key并进行删除操作* @returns {*}*/function deleteOldCaches() {return caches.keys().then(function (keys) {var all = keys.map(function (key) {if (key.indexOf(CACHE_PREFIX) !== -1 && key.indexOf(CACHE_VERSION) === -1){console.log('[SW]: Delete cache:' + key);return caches.delete(key);}});return Promise.all(all);});}//sw激活阶段,说明上一sw已失效self.addEventListener('activate', function(event) {event.waitUntil(// 遍历 caches 里所有缓存的 keys 值caches.keys().then(deleteOldCaches));});
idle
这个空闲状态一般是不可见的,这种一般说明sw的事情都处理完毕了,然后处于闲置状态了。
浏览器会周期性的轮询,去释放处于idle的sw占用的资源。
fetch
该阶段是sw最为关键的一个阶段,用于拦截代理所有指定的请求,并进行对应的操作。
所有的缓存部分,都是在该阶段,这里举一个简单的例子:
//监听浏览器的所有fetch请求,对已经缓存的资源使用本地缓存回复self.addEventListener('fetch', function(event) {event.respondWith(caches.match(event.request).then(function(response) {//该fetch请求已经缓存if (response) {return response;}return fetch(event.request);}));});
生命周期大概讲清楚了,我们就以一个具体的例子来说明下原生的serviceworker是如何在生产环境中使用的吧。
举个栗子
我们可以以网易新闻的wap页为例,其针对不怎么变化的静态资源开启了sw缓存,具体的sw.js逻辑和解读如下:
'use strict';//需要缓存的资源列表var precacheConfig = [["https://static.ws.126.net/163/wap/f2e/milk_index/bg_img_sm_minfy.png","c4f55f5a9784ed2093009dadf1e954f9"],["https://static.ws.126.net/163/wap/f2e/milk_index/change.png","9af1b102ef784b8ff08567ba25f31d95"],["https://static.ws.126.net/163/wap/f2e/milk_index/icon-download.png","1c02c724381d77a1a19ca18925e9b30c"],["https://static.ws.126.net/163/wap/f2e/milk_index/icon-login-dark.png","b59ba5abe97ff29855dfa4bd3a7a9f35"],["https://static.ws.126.net/163/wap/f2e/milk_index/icon-refresh.png","a5b1084e41939885969a13f8dbc88abd"],["https://static.ws.126.net/163/wap/f2e/milk_index/icon-video-play.png","065ff496d7d36345196d254aff027240"],["https://static.ws.126.net/163/wap/f2e/milk_index/icon.ico","a14e5365cc2b27ec57e1ab7866c6a228"],["https://static.ws.126.net/163/wap/f2e/milk_index/iconfont_1.eot","e4d2788fef09eb0630d66cc7e6b1ab79"],["https://static.ws.126.net/163/wap/f2e/milk_index/iconfont_1.svg","d9e57c341608fddd7c140570167bdabb"],["https://static.ws.126.net/163/wap/f2e/milk_index/iconfont_1.ttf","f422407038a3180bb3ce941a4a52bfa2"],["https://static.ws.126.net/163/wap/f2e/milk_index/iconfont_1.woff","ead2bef59378b00425779c4ca558d9bd"],["https://static.ws.126.net/163/wap/f2e/milk_index/index.5cdf03e8.js","6262ac947d12a7b0baf32be79e273083"],["https://static.ws.126.net/163/wap/f2e/milk_index/index.bc729f8a.css","58e54a2c735f72a24715af7dab757739"],["https://static.ws.126.net/163/wap/f2e/milk_index/logo-app-bohe.png","ac5116d8f5fcb3e7c49e962c54ff9766"],["https://static.ws.126.net/163/wap/f2e/milk_index/logo-app-mail.png","a12bbfaeee7fbf025d5ee85634fca1eb"],["https://static.ws.126.net/163/wap/f2e/milk_index/logo-app-manhua.png","b8905b119cf19a43caa2d8a0120bdd06"],["https://static.ws.126.net/163/wap/f2e/milk_index/logo-app-open.png","b7cc76ba7874b2132f407049d3e4e6e6"],["https://static.ws.126.net/163/wap/f2e/milk_index/logo-app-read.png","e6e9c8bc72f857960822df13141cbbfd"],["https://static.ws.126.net/163/wap/f2e/milk_index/logo-site.png","2b0d728b46518870a7e2fe424e9c0085"],["https://static.ws.126.net/163/wap/f2e/milk_index/version_no_pic.png","aef80885188e9d763282735e53b25c0e"],["https://static.ws.126.net/163/wap/f2e/milk_index/version_pc.png","42f3cc914eab7be4258fac3a4889d41d"],["https://static.ws.126.net/163/wap/f2e/milk_index/version_standard.png","573408fa002e58c347041e9f41a5cd0d"]];var cacheName = 'sw-precache-v3-new-wap-index-' + (self.registration ? self.registration.scope : '');var ignoreUrlParametersMatching = [/^utm_/];var addDirectoryIndex = function(originalUrl, index) {var url = new URL(originalUrl);if (url.pathname.slice(-1) === '/') {url.pathname += index;}return url.toString();};var cleanResponse = function(originalResponse) {// If this is not a redirected response, then we don't have to do anything.if (!originalResponse.redirected) {return Promise.resolve(originalResponse);}// Firefox 50 and below doesn't support the Response.body stream, so we may// need to read the entire body to memory as a Blob.var bodyPromise = 'body' in originalResponse ?Promise.resolve(originalResponse.body) :originalResponse.blob();return bodyPromise.then(function(body) {// new Response() is happy when passed either a stream or a Blob.return new Response(body, {headers: originalResponse.headers,status: originalResponse.status,statusText: originalResponse.statusText});});};var createCacheKey = function(originalUrl, paramName, paramValue,dontCacheBustUrlsMatching) {// Create a new URL object to avoid modifying originalUrl.var url = new URL(originalUrl);// If dontCacheBustUrlsMatching is not set, or if we don't have a match,// then add in the extra cache-busting URL parameter.if (!dontCacheBustUrlsMatching ||!(url.pathname.match(dontCacheBustUrlsMatching))) {url.search += (url.search ? '&' : '') +encodeURIComponent(paramName) + '=' + encodeURIComponent(paramValue);}return url.toString();};var isPathWhitelisted = function(whitelist, absoluteUrlString) {// If the whitelist is empty, then consider all URLs to be whitelisted.if (whitelist.length === 0) {return true;}// Otherwise compare each path regex to the path of the URL passed in.var path = (new URL(absoluteUrlString)).pathname;return whitelist.some(function(whitelistedPathRegex) {return path.match(whitelistedPathRegex);});};var stripIgnoredUrlParameters = function(originalUrl,ignoreUrlParametersMatching) {var url = new URL(originalUrl);// Remove the hash; see https://github.com/GoogleChrome/sw-precache/issues/290url.hash = '';url.search = url.search.slice(1) // Exclude initial '?'.split('&') // Split into an array of 'key=value' strings.map(function(kv) {return kv.split('='); // Split each 'key=value' string into a [key, value] array}).filter(function(kv) {return ignoreUrlParametersMatching.every(function(ignoredRegex) {return !ignoredRegex.test(kv[0]); // Return true iff the key doesn't match any of the regexes.});}).map(function(kv) {return kv.join('='); // Join each [key, value] array into a 'key=value' string}).join('&'); // Join the array of 'key=value' strings into a string with '&' in between eachreturn url.toString();};var hashParamName = '_sw-precache';//定义需要缓存的url列表var urlsToCacheKeys = new Map(precacheConfig.map(function(item) {var relativeUrl = item[0];var hash = item[1];var absoluteUrl = new URL(relativeUrl, self.location);var cacheKey = createCacheKey(absoluteUrl, hashParamName, hash, false);return [absoluteUrl.toString(), cacheKey];}));//把cache中的url提取出来,进行去重操作function setOfCachedUrls(cache) {return cache.keys().then(function(requests) {//提取urlreturn requests.map(function(request) {return request.url;});}).then(function(urls) {//去重return new Set(urls);});}//sw安装阶段self.addEventListener('install', function(event) {event.waitUntil(//首先尝试取出存在客户端cache中的数据caches.open(cacheName).then(function(cache) {return setOfCachedUrls(cache).then(function(cachedUrls) {return Promise.all(Array.from(urlsToCacheKeys.values()).map(function(cacheKey) {//如果需要缓存的url不在当前cache中,则添加到cacheif (!cachedUrls.has(cacheKey)) {//设置same-origin是为了兼容旧版本safari中其默认值不为same-origin,//只有当URL与响应脚本同源才发送 cookies、 HTTP Basic authentication 等验证信息var request = new Request(cacheKey, {credentials: 'same-origin'});return fetch(request).then(function(response) {//通过fetch api请求资源if (!response.ok) {throw new Error('Request for ' + cacheKey + ' returned a ' +'response with status ' + response.status);}return cleanResponse(response).then(function(responseToCache) {//并设置到当前cache中return cache.put(cacheKey, responseToCache);});});}}));});}).then(function() {//强制跳过等待阶段,进入激活阶段return self.skipWaiting();}));});self.addEventListener('activate', function(event) {//清除cache中原来老的一批相同key的数据var setOfExpectedUrls = new Set(urlsToCacheKeys.values());event.waitUntil(caches.open(cacheName).then(function(cache) {return cache.keys().then(function(existingRequests) {return Promise.all(existingRequests.map(function(existingRequest) {if (!setOfExpectedUrls.has(existingRequest.url)) {//cache中删除指定对象return cache.delete(existingRequest);}}));});}).then(function() {//self相当于webworker线程的当前作用域//当一个 service worker 被初始注册时,页面在下次加载之前不会使用它。 claim() 方法会立即控制这些页面//从而更新客户端上的serviceworkerreturn self.clients.claim();}));});self.addEventListener('fetch', function(event) {if (event.request.method === 'GET') {// 标识位,用来判断是否需要缓存var shouldRespond;// 对url进行一些处理,移除一些不必要的参数var url = stripIgnoredUrlParameters(event.request.url, ignoreUrlParametersMatching);// 如果该url不是我们想要缓存的url,置为falseshouldRespond = urlsToCacheKeys.has(url);// 如果shouldRespond未false,再次验证var directoryIndex = 'index.html';if (!shouldRespond && directoryIndex) {url = addDirectoryIndex(url, directoryIndex);shouldRespond = urlsToCacheKeys.has(url);}// 再次验证,判断其是否是一个navigation类型的请求var navigateFallback = '';if (!shouldRespond &&navigateFallback &&(event.request.mode === 'navigate') &&isPathWhitelisted([], event.request.url)) {url = new URL(navigateFallback, self.location).toString();shouldRespond = urlsToCacheKeys.has(url);}// 如果标识位为trueif (shouldRespond) {event.respondWith(caches.open(cacheName).then(function(cache) {//去缓存cache中找对应的url的值return cache.match(urlsToCacheKeys.get(url)).then(function(response) {//如果找到了,就返回valueif (response) {return response;}throw Error('The cached response that was expected is missing.');});}).catch(function(e) {// 如果没找到则请求该资源console.warn('Couldn\'t serve response for "%s" from cache: %O', event.request.url, e);return fetch(event.request);}));}}});
这里的策略大概就是优先在cache中寻找资源,如果找不到再请求资源。可以看出,为了实现一个较为简单的缓存,还是比较复杂和繁琐的,所以很多工具就应运而生了。
Workbox
由于直接写原生的sw.js,比较繁琐和复杂,所以一些工具就出现了,而workbox是其中的佼佼者,由google团队推出。
简介
在 Workbox 之前,GoogleChrome 团队较早时间推出过 sw-precache 和 sw-toolbox 库,但是在 GoogleChrome 工程师们看来,workbox 才是真正能方便统一的处理离线能力的更完美的方案,所以停止了对 sw-precache 和 sw-toolbox 的维护。
使用者
有很多团队也是启用该工具来实现serviceworker的缓存,比如说:
基本配置
首先,需要在项目的sw.js文件中,引入workbox的官方js,这里用了我们自己的静态资源:
importScripts("https://edu-cms.nosdn.127.net/topics/js/workbox_9cc4c3d662a4266fe6691d0d5d83f4dc.js");
其中importScripts是webworker中加载js的方式。
引入workbox后,全局会挂载一个workbox对象
if (workbox) {console.log('workbox加载成功');} else {console.log('workbox加载失败');}
然后需要在使用其他的api前,提前使用配置
//关闭控制台中的输出workbox.setConfig({ debug: false });
也可以统一指定存储时cache的名称:
//设置缓存cachestorage的名称workbox.core.setCacheNameDetails({prefix:'edu-cms',suffix:'v1'});
precache
workbox的缓存分为两种,一种的precache,一种的runtimecache。
precache对应的是在installing阶段进行读取缓存的操作。它让开发人员可以确定缓存文件的时间和长度,以及在不进入网络的情况下将其提供给浏览器,这意味着它可以用于创建Web离线工作的应用。
工作原理
首次加载Web应用程序时,workbox会下载指定的资源,并存储具体内容和相关修订的信息在indexedDB中。
当资源内容和sw.js更新后,workbox会去比对资源,然后将新的资源存入cache,并修改indexedDB中的版本信息。
我们举一个例子:
workbox.precaching.precacheAndRoute(['./main.css']);
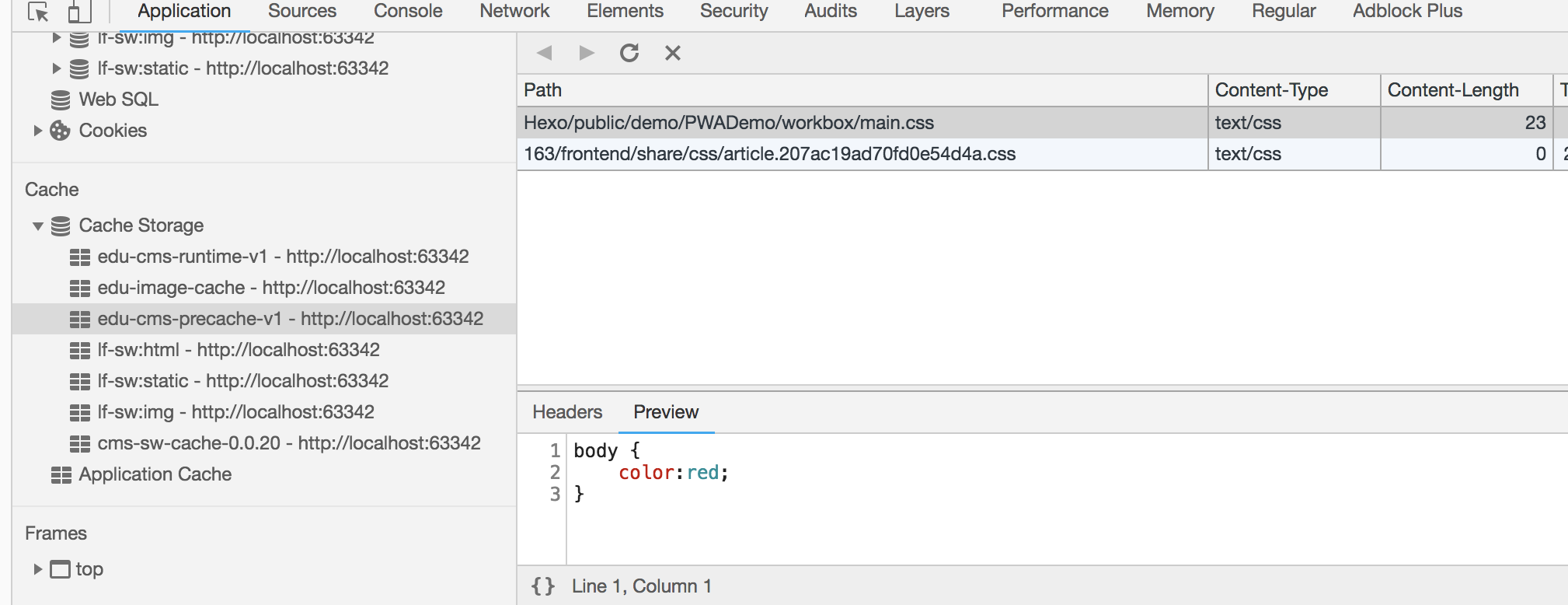
indexedDB中会保存其相关信息

这个时候我们把main.css的内容改变后,再刷新页面,会发现除非强制刷新,否则workbox还是会读取cache中存在的老的main.css内容。
即使我们把main.css从服务器上删除,也不会对页面造成影响。
所以这种方式的缓存都需要配置一个版本号。在修改sw.js时,对应的版本也需要变更。
使用实践
当然了,一般我们的一些不经常变的资源,都会使用cdn,所以这里自然就需要支持域外资源了,配置方式如下:
var fileList = [{url:'https://edu-cms.nosdn.127.net/topics/js/cms_specialWebCommon_js_f26c710bd7cd055a64b67456192ed32a.js'},{url:'https://static.ws.126.net/163/frontend/share/css/article.207ac19ad70fd0e54d4a.css'}];//precache 适用于支持跨域的cdn和域内静态资源workbox.precaching.suppressWarnings();workbox.precaching.precacheAndRoute(fileList, {"ignoreUrlParametersMatching": [/./]});
这里需要对应的资源配置跨域允许头,否则是不能正常加载的。且文件都要以版本文件名的方式,来确保修改后cache和indexDB会得到更新。
理解了原理和实践后,说明这种方式适合于上线后就不会经常变动的静态资源。
runtimecache
运行时缓存是在install之后,activated和fetch阶段做的事情。
既然在fetch阶段发送,那么runtimecache 往往应对着各种类型的资源,对于不同类型的资源往往也有不同的缓存策略。
缓存策略
workbox提供的缓存策划有以下几种,通过不同的配置可以针对自己的业务达到不同的效果:
staleWhileRevalidate
这种策略的意思是当请求的路由有对应的 Cache 缓存结果就直接返回,
在返回 Cache 缓存结果的同时会在后台发起网络请求拿到请求结果并更新 Cache 缓存,如果本来就没有 Cache 缓存的话,直接就发起网络请求并返回结果,这对用户来说是一种非常安全的策略,能保证用户最快速的拿到请求的结果。
但是也有一定的缺点,就是还是会有网络请求占用了用户的网络带宽。可以像如下的方式使用 State While Revalidate 策略:
workbox.routing.registerRoute(new RegExp('https://edu-cms\.nosdn\.127\.net/topics/'),workbox.strategies.staleWhileRevalidate({//cache名称cacheName: 'lf-sw:static',plugins: [new workbox.expiration.Plugin({//cache最大数量maxEntries: 30})]}));
networkFirst
这种策略就是当请求路由是被匹配的,就采用网络优先的策略,也就是优先尝试拿到网络请求的返回结果,如果拿到网络请求的结果,就将结果返回给客户端并且写入 Cache 缓存。
如果网络请求失败,那最后被缓存的 Cache 缓存结果就会被返回到客户端,这种策略一般适用于返回结果不太固定或对实时性有要求的请求,为网络请求失败进行兜底。可以像如下方式使用 Network First 策略:
//自定义要缓存的html列表var cacheList = ['/Hexo/public/demo/PWADemo/workbox/index.html'];workbox.routing.registerRoute(//自定义过滤方法function(event) {// 需要缓存的HTML路径列表if (event.url.host === 'localhost:63342') {if (~cacheList.indexOf(event.url.pathname)) return true;else return false;} else {return false;}},workbox.strategies.networkFirst({cacheName: 'lf-sw:html',plugins: [new workbox.expiration.Plugin({maxEntries: 10})]}));
cacheFirst
这个策略的意思就是当匹配到请求之后直接从 Cache 缓存中取得结果,如果 Cache 缓存中没有结果,那就会发起网络请求,拿到网络请求结果并将结果更新至 Cache 缓存,并将结果返回给客户端。这种策略比较适合结果不怎么变动且对实时性要求不高的请求。可以像如下方式使用 Cache First 策略:
workbox.routing.registerRoute(new RegExp('https://edu-image\.nosdn\.127\.net/'),workbox.strategies.cacheFirst({cacheName: 'lf-sw:img',plugins: [//如果要拿到域外的资源,必须配置//因为跨域使用fetch配置了//mode: 'no-cors',所以status返回值为0,故而需要兼容new workbox.cacheableResponse.Plugin({statuses: [0, 200]}),new workbox.expiration.Plugin({maxEntries: 40,//缓存的时间maxAgeSeconds: 12 * 60 * 60})]}));
networkOnly
比较直接的策略,直接强制使用正常的网络请求,并将结果返回给客户端,这种策略比较适合对实时性要求非常高的请求。
cacheOnly
这个策略也比较直接,直接使用 Cache 缓存的结果,并将结果返回给客户端,这种策略比较适合一上线就不会变的静态资源请求。
举个栗子
又到了举个栗子的阶段了,这次我们用淘宝好了,看看他们是如何通过workbox来配置serviceworker的:
//首先是异常处理self.addEventListener('error', function(e) {self.clients.matchAll().then(function (clients) {if (clients && clients.length) {clients[0].postMessage({type: 'ERROR',msg: e.message || null,stack: e.error ? e.error.stack : null});}});});self.addEventListener('unhandledrejection', function(e) {self.clients.matchAll().then(function (clients) {if (clients && clients.length) {clients[0].postMessage({type: 'REJECTION',msg: e.reason ? e.reason.message : null,stack: e.reason ? e.reason.stack : null});}});})//然后引入workboximportScripts('https://g.alicdn.com/kg/workbox/3.3.0/workbox-sw.js');workbox.setConfig({debug: false,modulePathPrefix: 'https://g.alicdn.com/kg/workbox/3.3.0/'});//直接激活跳过等待阶段workbox.skipWaiting();workbox.clientsClaim();//定义要缓存的htmlvar cacheList = ['/','/tbhome/home-2017','/tbhome/page/market-list'];//html采用networkFirst策略,支持离线也能大体访问workbox.routing.registerRoute(function(event) {// 需要缓存的HTML路径列表if (event.url.host === 'www.taobao.com') {if (~cacheList.indexOf(event.url.pathname)) return true;else return false;} else {return false;}},workbox.strategies.networkFirst({cacheName: 'tbh:html',plugins: [new workbox.expiration.Plugin({maxEntries: 10})]}));//静态资源采用staleWhileRevalidate策略,安全可靠workbox.routing.registerRoute(new RegExp('https://g\.alicdn\.com/'),workbox.strategies.staleWhileRevalidate({cacheName: 'tbh:static',plugins: [new workbox.expiration.Plugin({maxEntries: 20})]}));//图片采用cacheFirst策略,提升速度workbox.routing.registerRoute(new RegExp('https://img\.alicdn\.com/'),workbox.strategies.cacheFirst({cacheName: 'tbh:img',plugins: [new workbox.cacheableResponse.Plugin({statuses: [0, 200]}),new workbox.expiration.Plugin({maxEntries: 20,maxAgeSeconds: 12 * 60 * 60})]}));workbox.routing.registerRoute(new RegExp('https://gtms01\.alicdn\.com/'),workbox.strategies.cacheFirst({cacheName: 'tbh:img',plugins: [new workbox.cacheableResponse.Plugin({statuses: [0, 200]}),new workbox.expiration.Plugin({maxEntries: 30,maxAgeSeconds: 12 * 60 * 60})]}));
可以看出,使用workbox比起直接手撸来,要快很多,也明确很多。
原理
目前分析serviceworker和workbox的文章不少,但是介绍workbox原理的文章却不多。
这里简单介绍下workbox这个工具库的原理。
首先将几个我们产品用到的模块图奉上:
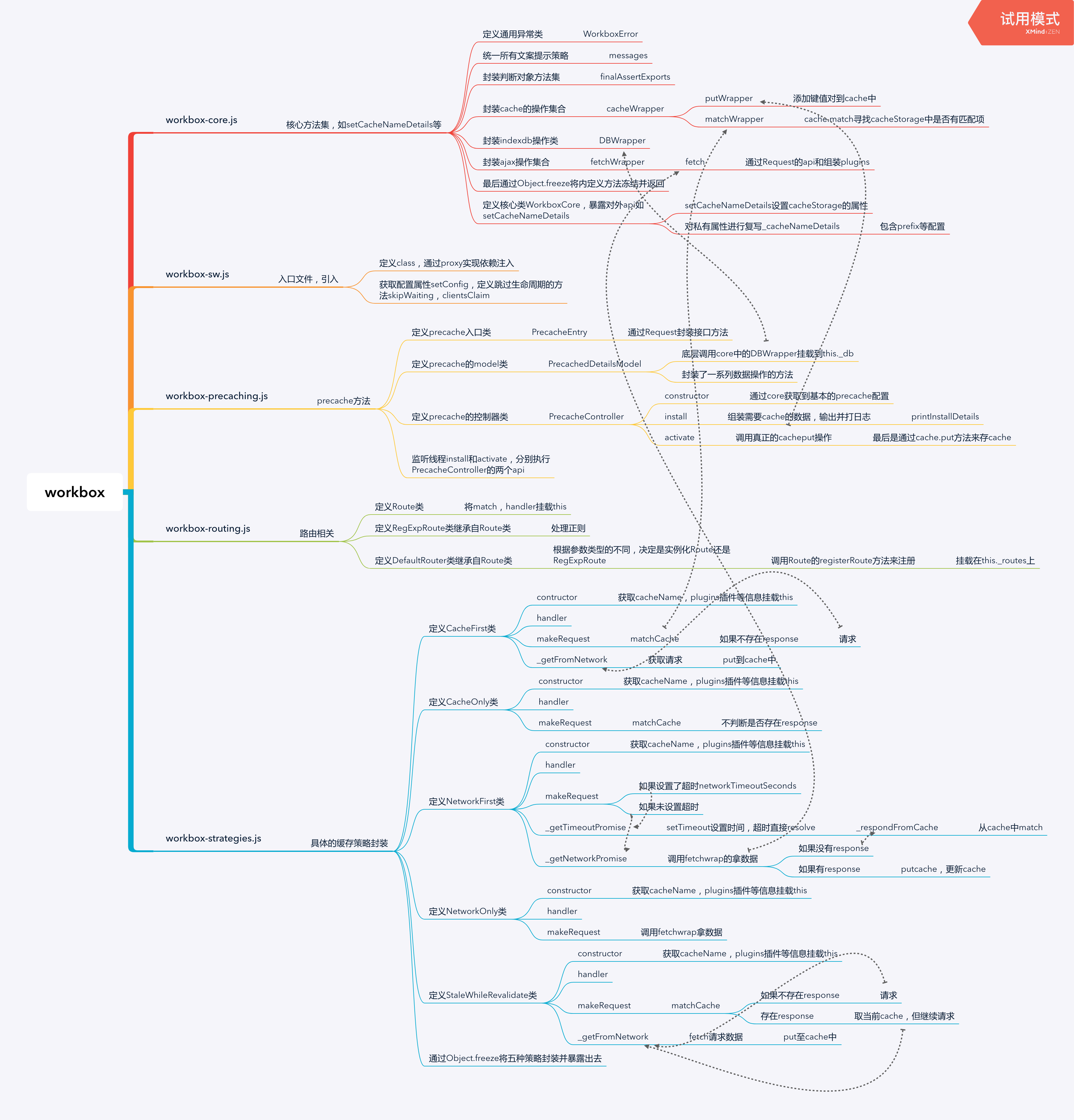
简单提几个workbox源码的亮点。
通过Proxy按需依赖
熟悉了workbox后会得知,它是有很多个子模块的,各个子模块再通过用到的时候按需importScript到线程中。
做到按需依赖的原理就是通过Proxy对全局对象workbox进行代理:
new Proxy(this, {get(t, s) {//如果workbox对象上不存在指定对象,就依赖注入该对象对应的脚本if (t[s]) return t[s];const o = e[s];return o && t.loadModule(`workbox-${o}`), t[s];}})
如果找不到对应模块,则通过importScripts主动加载:
/*** 加载前端模块* @param {Strnig} t*/loadModule(t) {const e = this.o(t);try {importScripts(e), (this.s = !0);} catch (s) {throw (console.error(`Unable to import module '${t}' from '${e}'.`), s);}}
通过freeze冻结对外暴露api
workbox.core模块中提供了几个核心操作模块,如封装了indexedDB操作的DBWrapper、对cacheStorage进行读取的cacheWrapper,以及发送请求的fetchWrapper和日志管理的logger等等。
为了防止外部对内部模块暴露出去的api进行修改,导致出现不可预估的错误,内部模块可以通过Object.freeze将api进行冻结保护:
var _private = /*#__PURE__*/Object.freeze({DBWrapper: DBWrapper,WorkboxError: WorkboxError,assert: finalAssertExports,cacheNames: cacheNames,cacheWrapper: cacheWrapper,fetchWrapper: fetchWrapper,getFriendlyURL: getFriendlyURL,logger: defaultExport});
总结
通过对serviceworker的理解和workbox的应用,可以进一步提升产品的性能和弱网情况下的体验。有兴趣的同学也可以对workbox的源码细细评读,其中还有很多不错的设计模式和编程风格值得学习。
- 前端项目websocket报错: VM57973 sockjs.min.js:2 Uncaught Error: Incompatible SockJS! Main site uses: "1.4.0", the iframe: "1.5.0".
VM57973 sockjs.min.js:2 Uncaught Error: Incompatible SockJS! Main site uses: "1.4.0", the iframe: "1.5.0".
- Cookie 的 SameSite 属性
Chrome 51 开始,浏览器的 Cookie 新增加了一个`SameSite`属性,用来防止 CSRF 攻击和用户追踪。
- serviceworker运用与实践
本文首先会简单介绍下前端的常见缓存方式,再引入serviceworker的概念,针对其原理和如何运用进行介绍。然后基于google推出的第三方库workbox,在产品中进行运用实践,并对其原理进行简要剖析。
- 深入理解浏览器的缓存机制
缓存可以说是性能优化中简单高效的一种优化方式了。一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,并且由于缓存文件可以重复利用,还可以减少带宽,降低网络负荷。 对于一个数据请求来说,可以分为发起网络请求、后端处理、浏览器响应三个步骤。浏览器缓存可以帮助我们在第一和第三步骤中优化性能。比如说直接使用缓存而不发起请求,或者发起了请求但后端存储的数据和前端一致,那么就没有必要再将数据回传回来,这样就减少了响应数据。
- TCP慢启动,拥塞控制,ECN 笔记
TCP在连接过程的三次握手完成后,开始传数据,并不是一开始向网络通道中发送大量的数据包,这样很容易导致网络中路由器缓存空间耗尽,从而发生拥塞;而是根据初始的cwnd大小逐步增加发送的数据量,cwnd初始化为1个最大报文段(MSS)大小(**这个值可配置不一定是1个MSS**);每当有一个报文段被确认,cwnd大小指数增长。
- 成为高手前必懂的TCP干货
我们在平时的开发过程中,或多或少都会涉猎到网络传输这块。 这篇文章,主要是整理一下 TCP 的一些知识要点,作为一名开发者来说,尽管有那么多的基础设施(框架、组件)帮我们屏蔽了这些细节。当我仍然认为了解它的一些基本原理必有些裨益,尤其是当你在分布式环境上遇到一些棘手问题时,一些原理性的知识可能会让你快速找到答案。
- Web 性能优化:Preload,Prefetch的使用及在 Chrome 中的优先级
- 使用WebP图像格式的完整指南
WebP,或非正式发音为 weppy ,是 Google开发者大约5年前推出的 一种图像格式 。
- Life of a Pixel,让你更透彻知道浏览器是如何工作
感谢Google巢鹏的提供的内容分享。Life of a Pixel这个演讲一开始是Chrome组新人入职的学习资料,给新人一个从高层次去看Chromium如何从HTML / CSS / JS 显示到屏幕的网页。这个演讲一直在更新,所以大家可以通过看这个演讲更新自己对Chromium的理解。
- chrome浏览器忽略证书报错
本地测试时,简易忽略chrome浏览器的证书问题
- http请求的完整过程
http请求的完整过程
- IE6/7浏览器兼容querySelectorAll、 querySelector
IE6/7浏览器兼容querySelectorAll、 querySelector
- 关于Preload, 你应该知道些什么?
preload作为一个新的web标准,旨在提高性能和为web开发人员提供更细粒度的加载控制。Preload使开发者能够自定义资源的加载逻辑,且无需忍受基于脚本的资源加载器带来的性能损失。
- 网站前后端性能优化的34条经验方法
网站前后端性能优化的34条经验方法
- [WEB安全]什么是XSRF?如何防范XSRF攻击!
CSRF(Cross-site request forgery跨站请求伪造,也被称成为“one click attack”或者session riding,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用。尽管听起来像跨站脚本(XSS),但它与XSS非常不同,并且攻击方式几乎相 左。XSS利用站点内的信任用户,而XSRF则通过伪装来自受信任用户的请求来利用受信任的网站。与XSS攻击相比,XSRF攻击往往不大流行(因此对其 进行防范的资源也相当稀少)和难以防范,所以被认为比XSS更具危险性
- http常用状态码
http常用状态码